


How It Started
Apache Cassandra is an open-source database developed by Facebook around 2008. It was developed to address the growing need for a database that could scale while maintaining no single point of failure. This helped power Facebook's inbox search feature. Today, it has exploded in growth and is used in a lot of Fortune 100 companies.
SQL vs. NoSQL
The first thing you need to know to understand Apache Cassandra is the difference between SQL (Structured Query Language) and NoSQL databases. If you are new to software development, it's more likely that you only ever interacted with SQL databases (MySQL, PostgreSQL, etc). They are easy to pick up and serve the basic needs of a variety of small to large-sized projects. As the scope of a project grows towards Big Data, you would look to solutions that offer more efficiency and scalability. This is where NoSQL comes in.
To simplify things, let's check out just a few key features in the picture below.
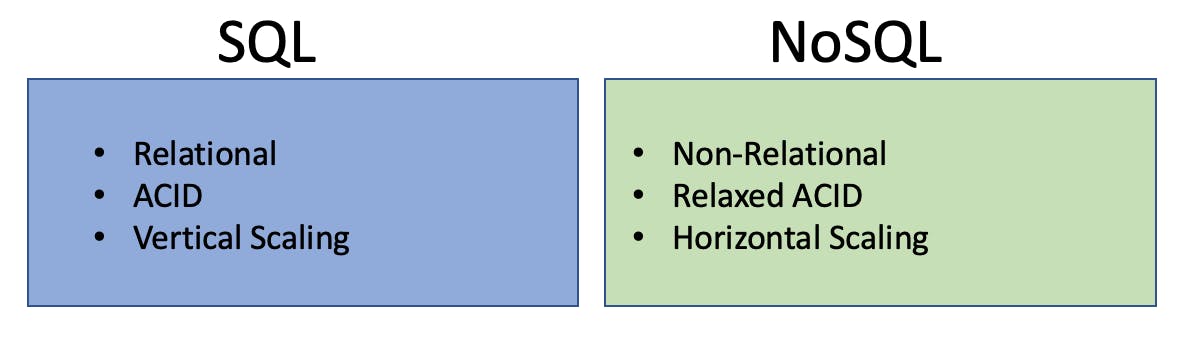
Relational vs. Non-Relational Databases
SQL databases are relational. Relational databases utilize tables that consist of columns and rows. Each row is identified with a unique key. When a database grows to many tables, it can associate records through the unique key, often called a primary or foreign key. In order to query this kind of database, we use SQL.
SQL databases optimize for storage by creating relations between tables. This results in very complex queries that will need more computing power.
NoSQL databases are non-relational. Non-relational databases take a much different approach to managing data. They don't use the same table, column, and row structure. These databases use a variety of different methods for storing data.
- Document stores data that is similar to JSON objects. This is more of a general-purpose type of database.
- Key-Value stores data based on a Key-Value pair. This is utilized for simple queries on large databases.
- Graph stores data in nodes. This is often used for social networks.
NoSQL databases optimize for compute and utilize very simple queries. This allows for these databases to scale compute resources quickly and efficiently.
ACID
ACID or Atomicity, Consistency, Isolation, and Durability is a framework used to describe the properties that define successful transactions within a database.
- Atomicity means a transaction takes place all at once
- Consistency means that the data remains consistent
- Isolation means transactions occur independently of each other
- Durability means the data persists in the case of system failures
When it comes to SQL databases, the ACID properties are followed. As a SQL database grows, ACID properties can start to fall apart. There is a loss of some consistency due to lag from our main database and replica. Failovers can be harder to recover from. This is just one of the few issues that arise when dealing with Big Data on a SQL database. As I mentioned earlier, SQL databases are best with small to medium-sized projects.
NoSQL databases relax these rules in order to make gains in other areas. These databases will often distribute servers which leads to eventual consistency. When any server fails, there will be enough copies of the data to recover without downtime. This leads to higher throughput and lower latency. This makes NoSQL a great use case for Big Data.
Vertical vs. Horizontal Scaling
SQL databases will often scale by adding more CPU/RAM, or vertical scaling. Eventually, you will hit a maximum CPU/RAM that you can scale up to. Horizontal scaling is used when separating portions of data. Given the nature of SQL databases, this becomes extremely tricky. It is difficult to know where and how to split up the database because of its relational nature.
NoSQL databases scale by adding more of the servers. These are the same type of servers that would already be deployed, just more of them. This allows for the distribution of data across a variety of servers.
Recap SQL vs NoSQL
Those are just a few ways to compare SQL vs NoSQL databases. That should give you a good sense of what you need to know to understand Cassandra.
Benefits of Apache Cassandra
Apache Cassandra is a fault-tolerant, high-performance, scalable, and decentralized NoSQL database. There's a lot to unpack in that one short sentence.
Fault-tolerance is the ability of your database to failover in case of disaster. If servers go down, you need your database to remain available. Cassandra uses multiple nodes placed on a ring.
Performance - Cassandra uses consistent hashing and organizes data into partitions to eventually store on distributed nodes. Data is often replicated on nodes. This write process is more complicated to implement due to replication, but its complexity allows for greatly improved read performance.
Scalable - Scaling is a very easy process with Cassandra. Simply, just add more nodes on the ring. You can easily scale up or down. This allows for linearly scaling.
Decentralized - There are no single points of failure due to the distributed nature of the nodes.
Basics
So...how does it work?
Other databases use a leader/follower structure, but Cassandra uses a peer-to-peer architecture. This is most apparent with the creation of many distributed nodes with replicated data.
Cassandra uses CQL (Cassandra Query Language) which is very similar to SQL. A few of the basic data types it uses are text, integer, and timestamp. It uses a UUID (Universally Unique Identifier) to identify records. This makes sure that all records are unique.
Let's dive deeper into the specifics.
Partitions
Partitions are essential for Cassandra. When we insert data into a table, we sort it into separate partitions based on specific data points. Down the line, this will allow us to find our data quickly. The partitions are stored on nodes. Each partition has a key that will decide its node placement on the ring. We will discuss the ring later on.
- PRIMARY KEY ((partition key), UUID)
Clustering Columns
This is an additional piece to help build out our Primary Key. In order to create more order and uniqueness within a partition, we will add to the primary key with a clustering column. Common clustering columns could be (name, date, place, etc). Within the partition, we will sort by the clustering column. You can add multiple clustering columns as necessary.
- PRIMARY KEY ((partition key), clustering column 1, .... clustering column N, UUID)
Nodes
Nodes can live in a variety of places, such as on a cloud provider, on-premises, or disks. Each node is responsible for all the data stored there. The data is stored in a hash table. We can read/write data based on hash keys. Nodes live at specific place on the ring.
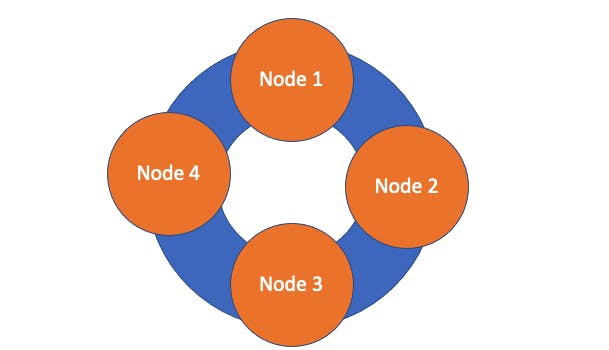
Ring
The Ring or Cluster groups the nodes together. The data is distributed across all the nodes on the ring. You might be thinking, how does it get to the right node?
There is a coordinator node that helps assign the data to the correct node. Each node is responsible for a range of data (token range). The coordinator receives data from the client and forwards that data to the correct node, and in return, the client is notified that the data was received properly.
Using a partitioner to evenly distribute data across the ring is essential to avoid hot spots. Hot spots are areas of concentrated data. Some nodes will be overflowing with data, while others have very little data in comparison. If those overflowing nodes fail, this can cause major issues within your database.
When a Node is placed on the cluster, there is no downtime. This is a great feature of Cassandra. Other databases have trouble with bringing replicas of data on/offline, but the ring helps us achieve zero downtime. The existing nodes on the ring calculate where the new node fits on the ring. They push all their data to the new node and it is placed on the ring.
Overview
That is the basic overview of the functionality of Cassandra. It utilizes well-sorted data within partitions, places that partition data onto nodes, and the nodes are organized on the ring. All these basics help build the foundation for fault tolerance, linear scalability, high performance, and decentralization. When considering a NoSQL database, Cassandra is a great choice and easy to pick up if you understand SQL. If you plan on working with Big Data in your career, learning Cassandra is an essential skill to have.